

Prove you are not a robot and digitise books and refine maps
Does it annoy you having to prove that you are not a robot, time and time again? Well what if you knew that you were doing it to protect your own interests and at the same time helping to digitalise classic books, refine maps and seek Artificial Intelligence solutions?
Proving that you are human and not a computer programme is mainly to prevent automated software (Robots/bots) and spammers from performing actions on your behalf. CAPTCHA is a programme that is used to protect you.
CAPTCHA
CAPTCHA (pronounced as cap-ch-uh) stands for Completely Automated Public Turing test to tell Computers and Humans Apart. Phew, now you see why it is called CAPTCHA! It was developed in 2000 at Carnegie Mellon University and has since been purchased by Google.
The technology used blocks spammers and bots that try to automatically harvest email addresses or try to automatically sign up for or make use of Web sites, blogs or forums. It protects your favourite websites from spam and abuse so that you don’t have to compete with robots and abusive scripts to access sites.
The main goal of CAPTCHA is to provide a test which is simple and straight forward for any human to answer but which is almost impossible for a computer to solve. CAPTCHA asks us to prove we are humans and not robots by typing text from a graphic.
Who Uses CAPTCHA?
CAPTCHAs are mainly used by websites that offer services like online polls and registration forms.
For example, Web-based email services like Gmail, Yahoo and Hotmail offer free email accounts for their users. CAPTCHAs are used at the sign up process to prevent spammers from using a “bot” to generate hundreds of spam mail accounts.
How does reCAPTCHA digitise a book?
Louis von Ahn, associate professor of computer science at Carnegie Mellon University and original creator of the CAPTCHA challenge screen, had the idea to put people’s time and effort (approximately 200 million CAPTCHAs were being typed daily by people around the world, the equivalent of approximately 500,000 hours each day) to good use through the reCAPTCHA project.
The “reCAPTCHA” project engages libraries and publishers who deliver OCR images to Web security sites. OCR technology is Optical Character Recognition. It allows you to convert different types of documents, such as scanned paper documents, PDF files or images captured by a digital camera into editable and search-able data. OCR automatically converts many words into digital text but about 30% of printed works before 1900 are unrecognisable to the system, chiefly due to faded text. It is these words that are used in CAPTCHAs, those that have been digitised but the computer cannot recognise.
CAPTCHA codes presented for verification are of two words. One is a control word, whose digitisation is known and the other requires verification. If enough people identify the latter, its digitisation is determined as fairly reliable.
‘So if you buy a ticket to an event or conduct an online transaction you are helping to convert classic books to digital format at a rate of around of 60 million words a day, which is the equivalent of around four million books a year.’
In fact 6% of the population has typed at least one word in this process!
I can’t always read my CAPTCHA
Unfortunately, as automated programs become better and better at deciphering CAPTCHA images, the CAPTCHA images need to become harder for the robots to read. According to Google advances in Artificial Intelligence have resulted in robot creations that are now able to solve even the most difficult variant of distorted text with 99.8% accuracy. In turn this makes it harder for us too. Sometimes the characters are so distorted that they can’t even be recognized by people with good vision, let alone visually handicapped individuals.
The reCAPTCHA team has been performing extensive research to learn how to better protect users from attackers. As a result, reCAPTCHA is now more adaptive and better-equipped to distinguish legitimate users from automated software.
Today the distorted letters serve less as a test of humanity and more as a medium of engagement to elicit a broad range of cues that characterize humans and bots. Now the entire user’s experience with the CAPTCHA; before, during and after they interact with it is taken into account. For example, the difference between bot and human can be revealed in clues as subtle as how a user (or a bot) moves a mouse in the brief moments before clicking the “I am not a robot” button.
Humans also drop clues that can establish whether we’re automated or not: IP addresses and cookies show our movements elsewhere on the Web and are taken into account.
Google has been integrating such automated bot-detection into its CAPTCHAs since 2013.
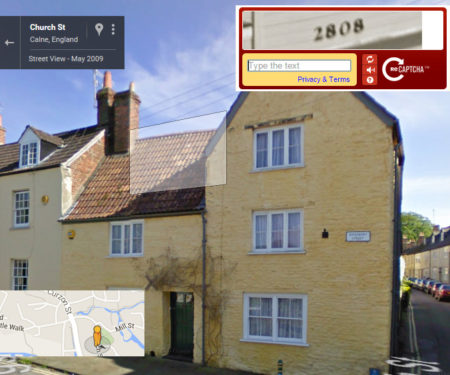
Captcha images can be used to identify addresses.
The majority of the Classic books have now been digitised
Today almost all of the classic books have been digitised. Solved CAPTCHAs are now used to digitise text, annotate images and build machine learning datasets. This helps us to preserve books, improve maps, and solve hard Artificial Intelligence problems.
You may now see numbers included in your CAPTCHAs. These are snippets from Google Street view. Now proving that you are human is helping Google to better identify street addresses, making Google Maps more precise and complete.
reCAPTCHA also helps to solve hard problems in Artificial Intelligence. High quality human labelled images are compiled into datasets that can be used to train Machine Learning systems. Research communities benefit from such efforts that help to build the next generation of ground breaking Artificial Intelligence solutions.
So when you are next asked to prove that you are human or not a robot perhaps you won’t mind as much now you know that you not only are you being protected but you may also be digitalising books, refining maps or helping to develop the future’s Artificial Intelligence solutions. Well done!
As you noted, the digital capture devices have better vision than most human. Your explanation is of little comfort to those us who are look a fuzzy images and trying figure out how many of them have dogs lifting a leg on a fire hydrant. Especially after you failed the test for the third time. Tonight I was trying to access the help system on several hundred dollar software program, but I could prove I was a human to get in. If security is this big an issue than take the site down. The purpose of the site was to help users. No matter how good the site is, if can’t be accessed, its just more clutter on the web and should be taken down. If security trumps usability, why publish at all?